Problem Domains
I came across a book about making your own operating system. While it’s extremely heavy in regard to assembly code manipulation there is an early section that suck out to me that I’d like to preserve here. Please checkout the full book here: https://github.com/tuhdo/os01 It was the first piece of literature that helped me to frame how exactly a problem interfaces between different systems and that need translation for the desired effect to occur.
Problem domains
In the real world, software engineering is not only focused on software, but also the problem domain it is trying to solve.
A problem domain is the part of the world where the computer is to pro-duce effects, together with the means available to produce them, directly or indirectly. (Kovitz, 1999)
A problem domain is anything outside of programming that a software engineer needs to understand to produce correct code that can achieve the desired effects. “Directly” means include anything that the software can control to produce the desired effects, e.g. keyboards, printers, monitors, other software, etc. “Indirectly” means anything not part of the soft-ware but relevant to the problem domain e.g. appropriate people to be informed by the software when some event happens, students that move to correct classrooms according to the schedule generated by the soft-ware. To write a finance application, a software engineer needs to learn sufficient finance concepts to understand the requirements of a customer and implement such requirements, correctly.
Requirements are the effects that the machine is to exert in the problem domain by virtue of its programming.
Programming alone is not too complicated; programming to solve a problem domain, is 1. Not only a software engineer needs to understand how to implement the software, but also the problem domain that it tries to solve, which might require in-depth expert knowledge. The software engineer must also select the right programming techniques that apply to the problem domain he is trying to solve because many techniques that are effective in one domain might not be in another. For example, many types of applications do not require performant written code, but a short time to market. In this case, interpreted languages are widely popular because it can satisfy such need. However, for writing huge 3D games or operating system, compiled languages are dominant because it can generate the most efficient code required for such applications.
Often, it is too much for a software engineer to learn non-trivial do-mains (that might require a bachelor degree or above to understand the domains). Also, it is easier for a domain expert to learn enough programming to break down the problem domain into parts small enough for the software engineers to implement. Sometimes, domain experts implement the software themselves.
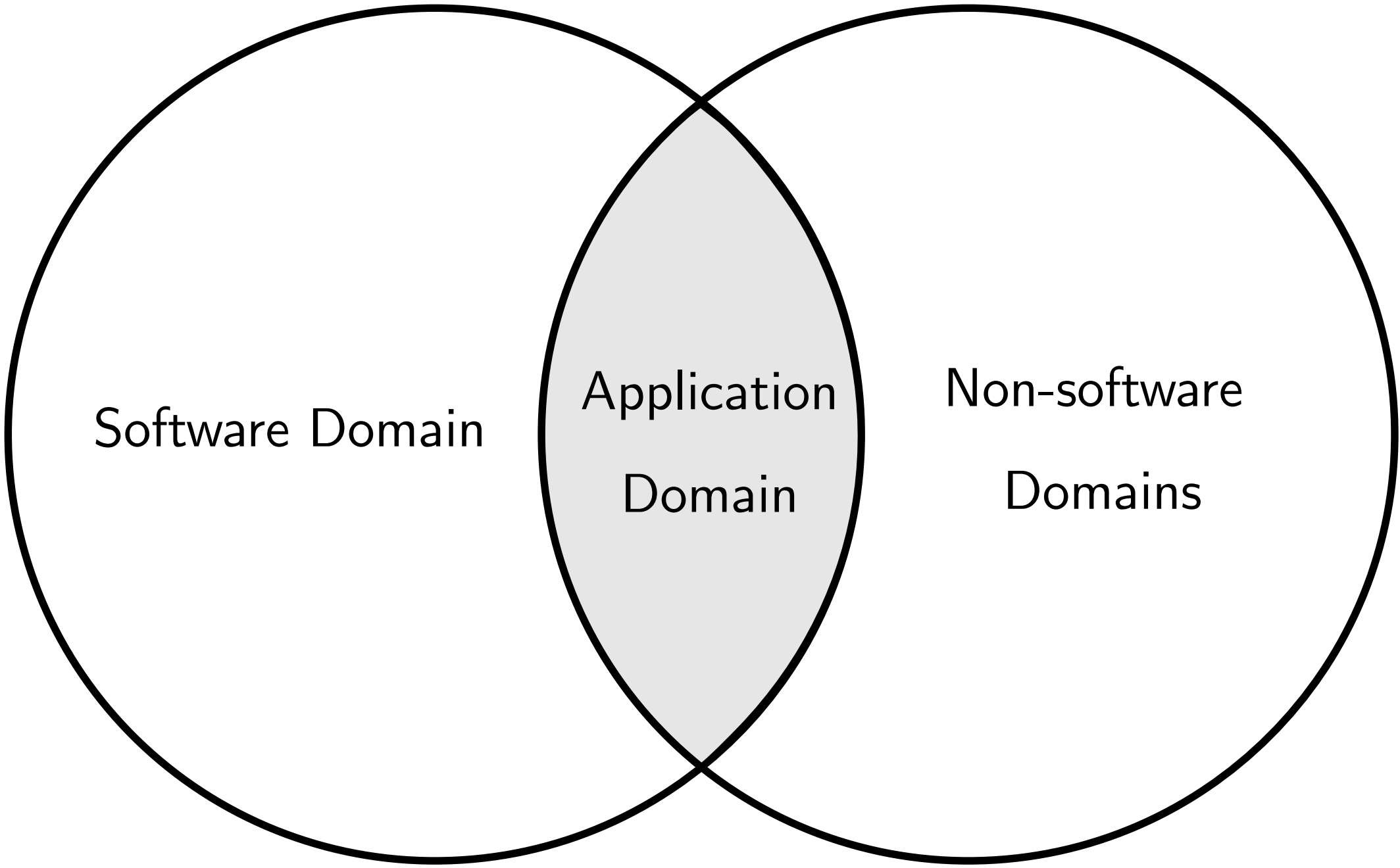
One example of such scenario is the domain that is presented in this book: operating system. A certain amount of electrical engineering (EE) knowledge is required to implement an operating system. If a computer science (CS) curriculum does not include minimum EE courses, students in the curriculum have little chance to implement a working operating system. Even if they can implement one, either they need to invest a significant amount of time to study on their own, or they fill code in a pre-defined framework just to understand high-level algorithms. For that rea-son, EE students have an easier time to implement an OS, as they only need to study a few core CS courses. In fact, only “C programming” and “Algorithms and Data Structures” classes are usually enough to get them started writing code for device drivers, and later generalize it into an operating system.
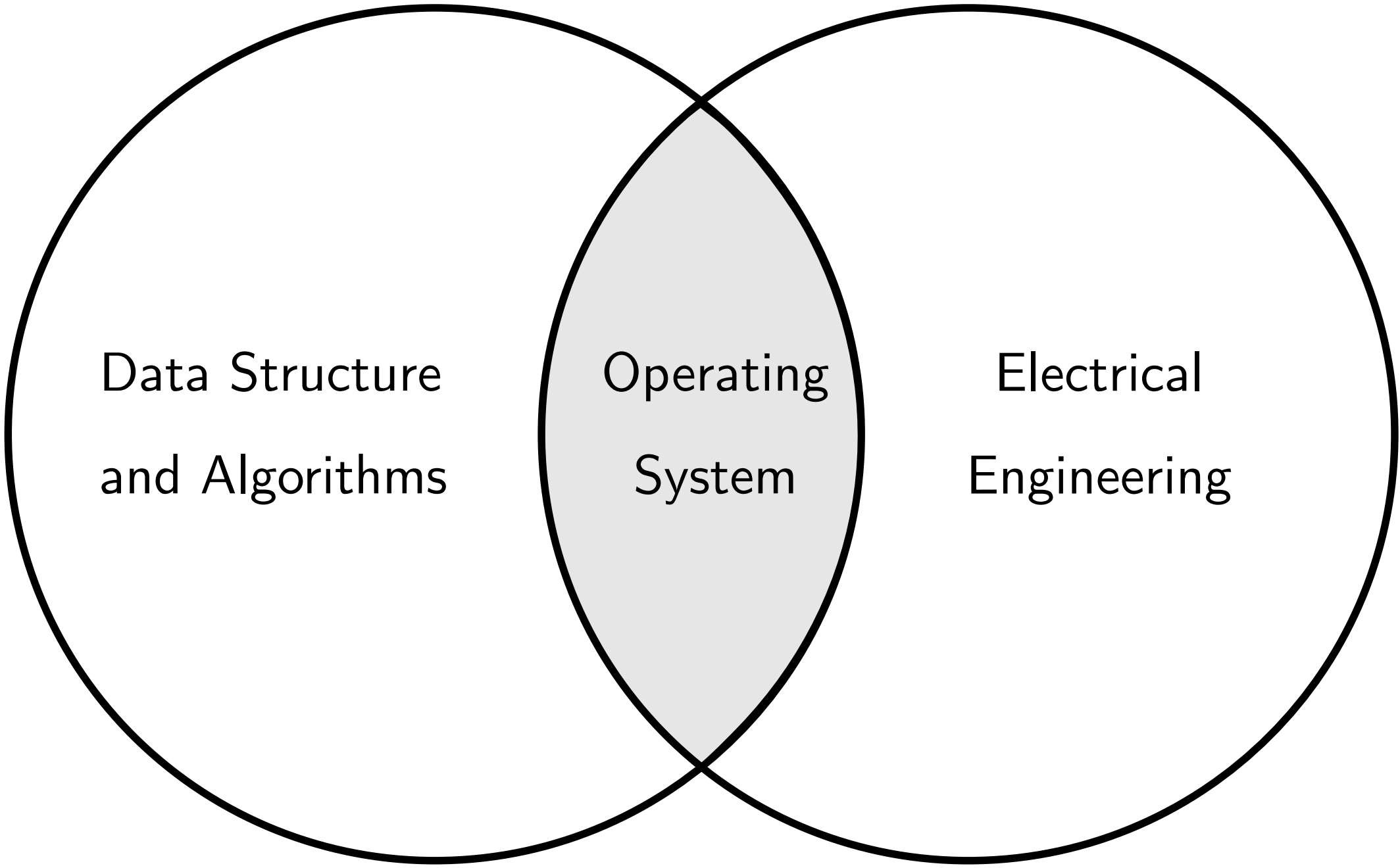
One thing to note is that software is its own problem domain. A problem domain does not necessarily divide between software and itself. Compilers, 3D graphics, games, cryptography, artificial intelligence, etc., are parts of software engineering domains (actually it is more of a computer science domain than a software engineering domain). In general, a software-exclusive domain creates software to be used by other software. Operating System is also a domain, but is overlapped with other domains such as electrical engineering. To effectively implement an operating system, it is required to learn enough of the external domain. How much learning is enough for a software engineer? At the minimum, a software engineer should be knowledgeable enough to understand the documents prepared by hard-ware engineers for using (i.e. programming) their devices.
Learning a programming language, even C or Assembly, does not mean a software engineer can automatically be good at hardware programming or any related low-level programming domains. One can spend 10 years, 20 years or his entire life writing C/C++ code, and he still cannot write an operating system, simply because of the ignorance of relevant domain knowledge. Just like learning English does not mean a person automat-ically becomes good at reading Math books written in English. Much more than that is needed. Knowing one or two programming languages is not enough. If a programmer writes software for a living, he had bet-ter be specialized in one or two problem domains outside of software if he does not want his job taken by domain experts who learn program-ming in their spare time.
1 We refer to the concept of “program-ming” here as sorneone able to write code in a language, but not necessary know any or all software engineering knowledge.
Wizard Magic Vibe Coding
I finally decided to boot back up my main desktop computer and try out some of the new “AI Coding Assistants” to see what they are capable of. The extensions Cline Code & Roo code do this by having a model interface with an IDE. With a local model you can even do the process fully offline. And with I made 2 simple tools. One was for query the GitHub API to get a list of my GitHub stars and the other was to make a semi-automated video editor.
My mind has gone from “gahh, I have to figure all this stuff out to make this program” to “oh, I’m done. Now what else can I add?”. Of course, there is going to be the eventual time when the project gets too complex and I’ll have to study an entire generated code base or start from scratch. But I don’t think I’ll ever get there (yet). Most of the tools I’m making now have a few primary purposes and objectives that have either been proprietary software or have a lackluster solution on GitHub. I fully believe that for the majority of non-developers a GUI (graphical-user-interface) is the main thing stopping people from trying a piece of software out.
Well guess what, now nobody has an excuse of “well that will take a lot of time to make it interactive, just use terminal”.
Prompt: “Make a GUI and Debug any problems”. Essentially done. It doesn’t even have to look pretty, just usable and doesn’t break. And if you don’t want it in the main code base? Separate it out.
So yeah, I get it now. I have been on the wire trying to figure out what cool stuff I can do with these new tools and sets of constraints. And while I still fully believe software developers will be needed (at-least in the short term) I can only see the positives of letting more people with more ideas make application that gives a solution to their problem.
Why do I still have a Job?
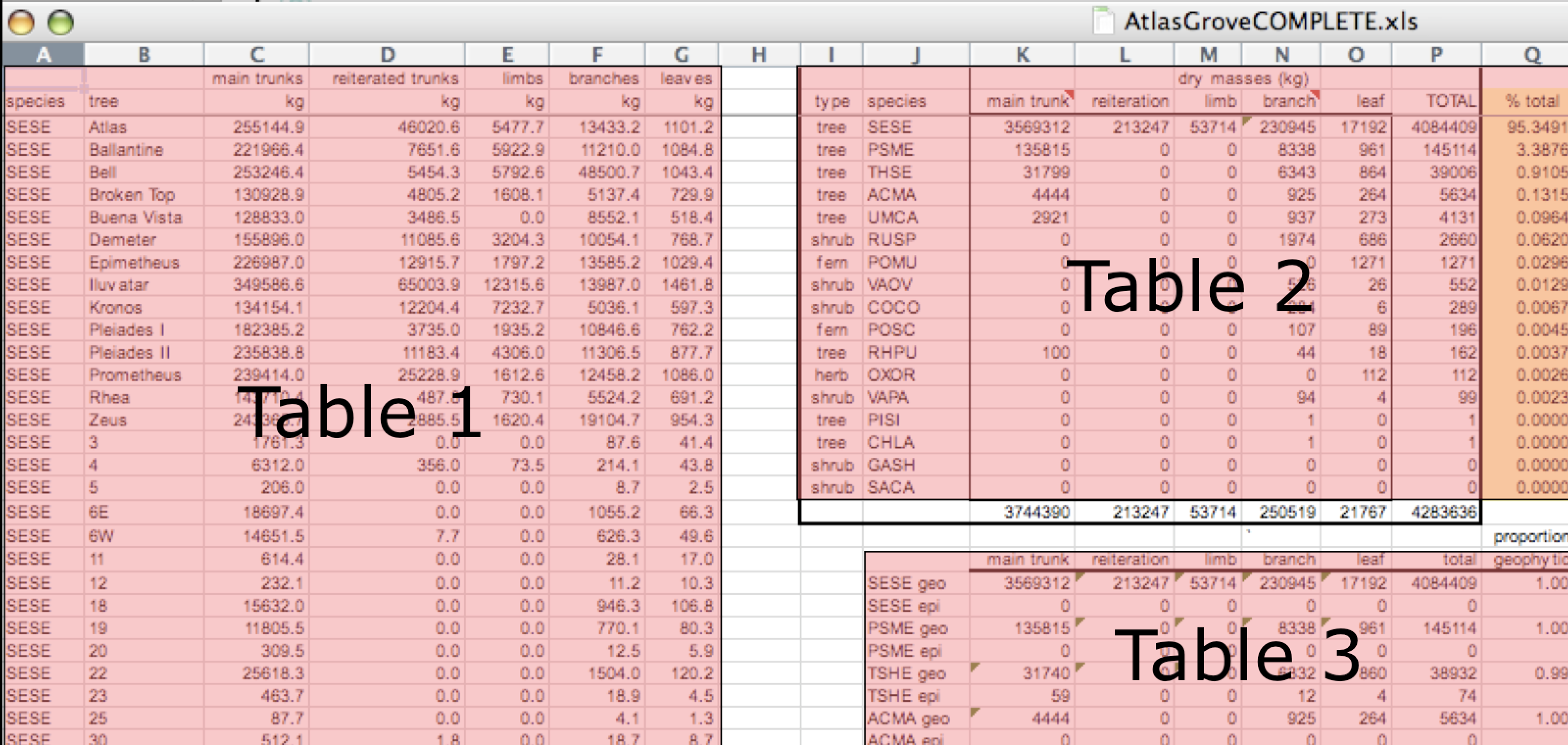
In around 2023 I first started working on a project utilizing MegaDetector (now Pytorch-Wildlife) that came about when I was trying to automate my animal classification and labeling job using image detection models as a research assistant. In that time I came across a book simply titled “Reproducible Analysis with R”. In section 6.4 there is simple an image titled “Multiple Tables” .
{kind=link}

It pictures one of the easiest ways that data can become unorganized - that there are different observations or pieces of data within the same row. This problem of course is relatively easy to fix if you put them into separate tables. However, this “fix” compounds over time as more imperfections take place, making it difficult to analyze or visualize the data.
Before I go in further, I’m going to make conflicting opinions because I hold the two foundational beliefs in regard to AI, LLMs, and Automation and why people will still have jobs in the coming future.
- When data is organized, there is little need for human labor. I fully believe most business task can be automated when data is structured.
- Current LLM (called “AI”, even when it’s not) systems, even with error correction practices and continuous improvement have to interface with the imperfect data formats that currently are solved in closed environments. Muddy data can never be cleaned without proper context.
Right now, the current work infrastructure is based in some conjunction of a messaging platform (email, teams) + software specific task management (Reconciliation application, tax application) + a project management platform (such as Jira, Ticket System). There have been attempts to broach this of course with the advent of Enterprise-Resource-Planning (ERP) systems. ERP systems reduce the problem of data silos by combining multiple business operations pipelines into a structured format. However, if there is ever a user error in either using the system or trying to not use the system (such as downloading the data to excel) then the purpose is lost.
When I read about the concept of “management execution apps” from Cal Newport’s book “A World Without Email” it made complete sense to me why currently a majority of hand-off task are still inefficient. In my current company we call this an “end-to-end business process” and in the broader broad of computer science a “data pipeline. They are inefficient because there is a lack of clarity and structure. Much of my current jobs, and many out there, are making sure that you’re pinging people enough times through email until they respond with the email that you need.
In Derek Thompson’s podcast ‘Plain English’ there was an idea that came up of “Emptying email inbox as a competency of AGI”. I think this is an extremely inefficient and incorrect way to think about the future of AGI and job replacement with the context of “Live in the future, then build what’s missing” from Paul Graham. By using a metric of email - We are solving today’s problems, not building tomorrow’s solution.
To give an example of this - the RSS/Atom Feed. There is a plethora of reasons why it was not widely adopted. (such as not being able to collect information about who subscribes to a feed, aka data collection instead of privacy). But it is a dramatically more energy friendly way to post content to followers than newsletters, that require you to send an email individually to each subscriber.
The Newsletter solved today’s problems, RSS built tomorrow’s solution.
LLMs/AI solve today’s problem. Structured data builds tomorrow’s solutions
For the area I live in of Hampton roads there are collection of RSS feed and Newsletter’s to know what’s going to happen in the area. You can use an LLM to organize this data. [For example - the project I’m currently working on at-least has 20+ sources that I’m pulling from.]. However, it would have been much easier for me if everything was an RSS feed so I wouldn’t have to HTTPS scrape a website individually for their blog post and updates.
Then I came across ai-2027 that “predict[s] that the impact of superhuman AI over the next decade will be enormous, exceeding that of the Industrial Revolution. This raised an eyebrow for me.
For those that have any experience with power automate, n8n, Zapier, IFTTT, Decisions.ai there are many finite and specific pieces at play that make a workflow either succeed or fail. A huge portion of that is error correction and decisions trees. When I was recently trying to make my own process, I came upon a very particular problem. When I was parsing an HTML document to get a string of characters for my URL link. Every single time through an LLM model it would mess up the link and change it up even with variability set to zero. I ultimately gave up because the marginal benefit was not there when a model was able to efficiently pull all other information and links.
To say again: LLMs/AI solve today’s problem. Structured data builds tomorrow’s solutions
- Why don’t we have a fully auditable government? Because of Data Silos
- Why do I still have a job? Because of data silos, unorganized data, and limited business structurization relative to what is needed for automation
- Why don’t we have a unified healthcare information system? Because of Data Silos and Political Factors
- In essence, why don’t we have XYZ when it comes to unification of a system? Because there is a massive infrastructure, cultural, and monetary cost associated with change.
So, what exactly do I mean by structured data? Going back to the beginning of the article there is a different between data being structured and data being organized. The easiest way to think about it is bring the mindset of “can I make this into a digital form that people can enter information into”.
- Grouping the M&M candy by color is organized
- Labeling each M&M candy...
Jekyll Theme Chirpy Setup Resources
Some helpful resources that help me to setup this website.
- The Theme Itself (Chirpy): https://github.com/cotes2020/jekyll-theme-chirpy/tree/master
- Adding Comments: https://www.nymanska.com/posts/Giscus-comments/
- Carbon Usage: https://www.websitecarbon.com/website/useplunk.com/
- Guide Setup with Cloudflare: https://medium.com/@svenvanginkel/build-a-blog-with-jekyll-chirpy-on-cloudflare-pages-f204bc538af9
- Additional Setup: https://blog.warnov.com/tags/chirpy/
- Changing Profile Picture: https://talk.jekyllrb.com/t/how-to-change-logo-in-jekyll-chirpy-theme/8180/4
The Altered Shopping Cart Test - The Nonprofit Test
How did this come about?
“If you received $10k from other people and had influential power in a nonprofit organization what would you do?” People seem to flat out fail this test because most of the time they say ‘I’d donate it to charity’ This recently came up because I recently (link to other article) - made my own nonprofit to use my company nonprofit benefits matching. I am now in a situation in which I’d like to make a positive and unique impact on my community but do not know what to do. Hence, the creation of this question and test for other people.
A rewrite of The Shopping Cart test, The Nonprofit Test
The nonprofit test is the ultimate litmus test for whether a person is capable of self-philanthropy. To donate money to those in need is an easy, convenient task and one which we all recognize as the correct, appropriate thing to do. To help those in need is objectively right. There are no situations other than dire emergencies in which a person is not able to spend the money. Simultaneously, it is not illegal to abandon the nonprofit money. Therefore, the nonprofit organization presents itself as the apex example of whether a person will do what is right without being forced to do it. No one will punish you for not spending nonprofit money, no one will fine you or kill you for not returning the donated nonprofit money. You must lead the nonprofit organization out of the goodness of your own heart. You must delegate the money because it is the right thing to do. Because it is correct. A person who is unable to do this is no better than your average person, who can only be made to do what is right by guilt tripping them or offering them a tax write-off. The nonprofit test is what determines whether a person is a good or bad member of society.
What is the shopping cart test?
The shopping cart is the ultimate litmus test for whether a person is capable of self-governing. To return the shopping cart is an easy, convenient task and one which we all recognize as the correct, appropriate thing to do. To return the shopping cart is objectively right. There are no situations other than dire emergencies in which a person is not able to return their cart. Simultaneously, it is not illegal to abandon your shopping cart. Therefore, the shopping cart presents itself as the apex example of whether a person will do what is right without being forced to do it. No one will punish you for not returning the shopping cart, no one will fine you or kill you for not returning the shopping cart. You must return the shopping cart out of the goodness of your own heart. You must return the shopping cart because it is the right thing to do. Because it is correct. A person who is unable to do this is no better than an animal, an absolute savage who can only be made to do what is right by threatening them with a law and the force that stands behind it. The Shopping Cart is what determines whether a person is a good or bad member of society.